MySQL索引
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,查询速度就能提高千百倍。
例子
首先,创建一个有800万条数据的表
-- 创建测试数据库 tmp
CREATE DATABASE tmp;
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
DELIMITER $$
#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
# concat 函数 : 连接函数mysql函数
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
#这里我们又自定了一个函数,返回一个随机的部门号
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(10+RAND()*500);
RETURN i;
END $$
#创建一个存储过程, 可以添加雇员
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0
#autocommit = 0 含义: 不要自动提交
SET autocommit = 0; #默认不提交sql语句
REPEAT
SET i = i + 1;
#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
INSERT INTO emp VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
#commit整体提交所有sql语句,提高效率
COMMIT;
END $$
#添加8000000数据
CALL insert_emp(100001,8000000)$$
#命令结束符,再重新设置为;
DELIMITER ;
以上创建800万条数据执行时间为九分十六秒
SELECT COUNT(*) FROM emp;
-- 在没有创建索引时,我们查询一条记录
SELECT * FROM emp WHERE empno = 1234567 -- 使用了9.29秒
-- 使用索引来优化一下
-- 在没有创建索引前,emp.ibd的大小是524m
-- 创建empno索引后emp.ibd的大小是655m[索引本身也会占用空间]
-- 创建ename索引后,emp.ibd的大小是827m
-- empno_index :索引名称
-- on emp(empno):表示在emp表的empno列创建索引
CREATE INDEX empno_index ON emp(empno)
-- 在创建索引后查询一条记录
SELECT * FROM emp WHERE empno = 1234567 -- 使用了0.003秒
-- 创建索引后只对创建索引的列有效
SELECT * FROM emp WHERE ename = 'KsInoJ';-- 使用了9.664秒
CREATE INDEX ename_index ON emp(ename)
SELECT * FROM emp WHERE ename = 'KsInoJ';-- 使用了0.914秒
可以看到在创建了索引之后查询速度有了飞速的提升
1.索引原理
- 索引的原理
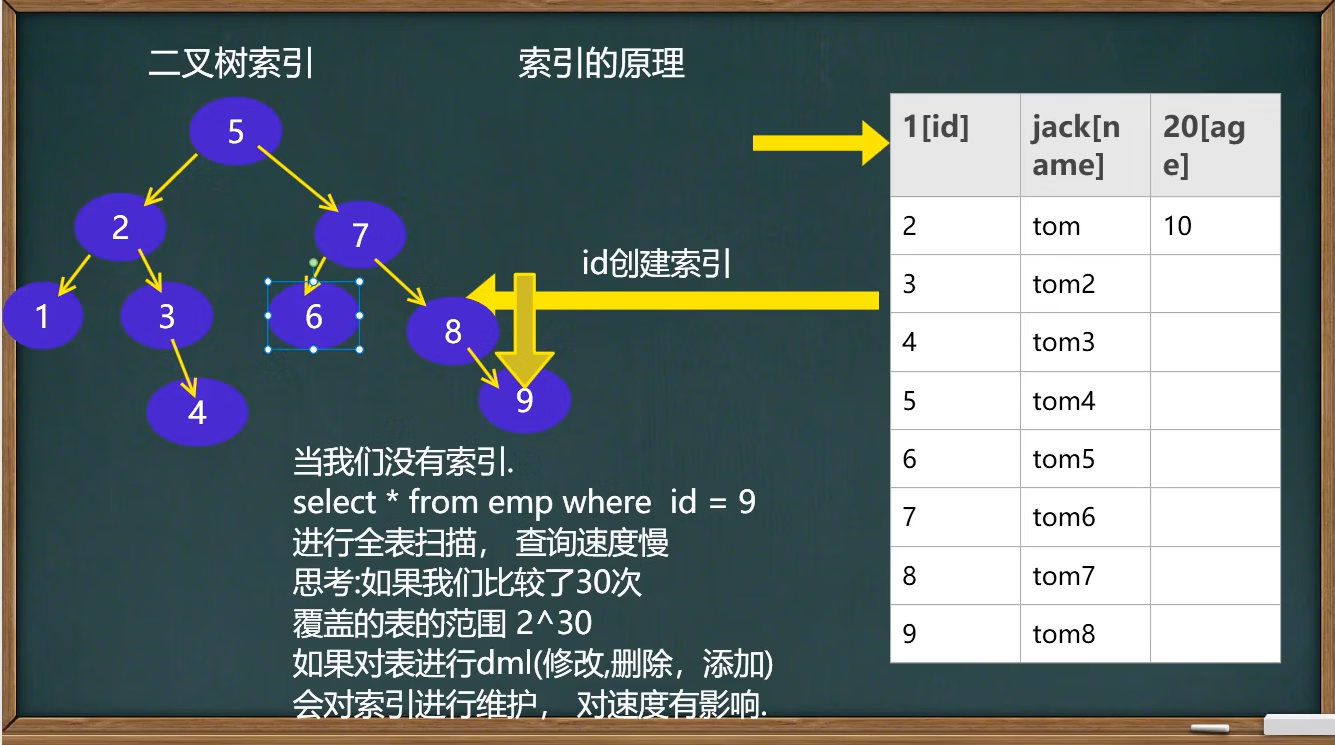
没有索引为什么会变慢?因为会进行全表扫描
有索引为什么会变快?会形成一个索引的数据结构,比如二叉树、B树等
- 索引的代价:
- 磁盘占用
- 对dml(update delete insert)语句的效率影响
虽然索引对dml语句效率有影响,但是在项目开发中绝大多数操作是select,利大于弊
2.索引的使用
- 索引的类型
主键索引,主键自动地为主键索引(类型 primary key)
唯一索引(unique),unique索引
普通索引(index)
全文索引(fulltext)[适用于MylSAM]
一般开发不使用mysql自带的全文索引,而是使用:全文搜索 Solr 和 ElasticSearch(ES)
- 语法
创建索引
方法一:
create [unique] index index_name on table_name(col_name[(length)] [asc|desc],...);方法二:
alter table table_name add index [index_name] (index_col_name,...);添加主键索引
alter table 表名 add primary key(列名,...);删除索引
DROP INDEX id_name ON table_name;alter table table_name drop index index_name;删除主键索引
ALTER TABLE table_name DROP PRIMARY KEY;查询索引(三种方式)
show index(es) from table_name; show keys from table_name; desc table_name;
例子
-- 演示mysql索引的使用
-- 创建索引
CREATE TABLE t25(
id INT,
`name` VARCHAR(32)
);
-- 1.查询表是否有索引
SHOW INDEXES FROM t25;
-- 2.添加索引
-- 2.1添加唯一索引
CREATE UNIQUE INDEX id_index ON t25 (id);
-- 2.2添加普通索引
CREATE INDEX name_index ON t25 (`name`);
-- 如何选择?
-- 如果某列的值不会重复,则优先考虑使用unique索引,否则使用普通索引
-- 添加普通索引方式2
ALTER TABLE t25 ADD INDEX id_index (id);
-- 2.3添加主键索引
CREATE TABLE t26(
id INT,
`name` VARCHAR(32)
);
ALTER TABLE t26 ADD PRIMARY KEY(id);
SHOW INDEXES FROM t26;
-- 删除索引
DROP INDEX id_index ON t25;
DROP INDEX name_index ON t25;
-- 删除主键索引
ALTER TABLE t26 DROP PRIMARY KEY;
-- 修改索引:先删除,再添加新的索引
-- 查询索引
-- 方式1
SHOW INDEX FROM t25;
-- 方式2
SHOW INDEXES FROM t25;
-- 方式3
SHOW KEYS FROM t25;
-- 方式4
DESC t25;
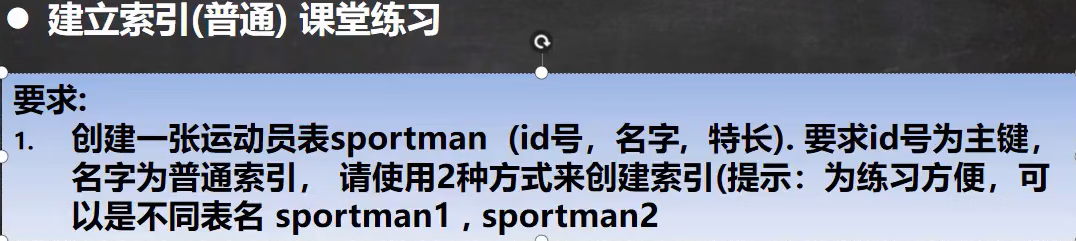
- 练习


3.小结
那些列上适合使用索引?
- 较频繁地作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引
- 更新非常频繁的字段不适合创建索引
- 不会出现在where子句中的字段不该创建索引
标签: # MySQL
留言评论