查表算法,无疑也是一种非常常用、有效而且快捷的算法,我们在很多算法的加速过程中都能看到他的影子,在图像处理中,尤其常用,比如我们常见的各种基于直方图的增强,可以说,在photoshop中的调整菜单里80%的算法都是用的查表,因为他最终就是用的曲线调整。
普通的查表就是提前建立一个表,然后在执行过程中算法计算出一个索引值,从表中查询索引对应的表值,并赋值给目标地址,比如我们常用的曲线算法如下所示:
int IM_Curve_PureC(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, unsigned char *TableB, unsigned char *TableG, unsigned char *TableR)
{
int Channel = Stride / Width;if (Channel == 1)
{
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Width; X++)
{
LinePD[X] = TableB[LinePS[X]];
}
}
}
else if (Channel == 3)
{
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Width; X++)
{
LinePD[0] = TableB[LinePS[0]];
LinePD[1] = TableG[LinePS[1]];
LinePD[2] = TableR[LinePS[2]];
LinePS += 3;
LinePD += 3;
}
}
}return IM_STATUS_OK;
}
通常我们认为这样的算法是很高效的,当然,我们其实还可以做一定的优化,比如使用下面的四路并行:
int IM_Curve_PureC(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, unsigned char *TableB, unsigned char *TableG, unsigned char *TableR)
{
int Channel = Stride / Width;
if ((Channel != 1) && (Channel != 3)) return IM_STATUS_INVALIDPARAMETER;
if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE;
if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER;
int BlockSize = 4, Block = Width / BlockSize;
if (Channel == 1)
{
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
LinePD[X + 0] = TableB[LinePS[X + 0]];
LinePD[X + 1] = TableB[LinePS[X + 1]];
LinePD[X + 2] = TableB[LinePS[X + 2]];
LinePD[X + 3] = TableB[LinePS[X + 3]];
}
for (int X = Block * BlockSize; X < Width; X++)
{
LinePD[X] = TableB[LinePS[X]];
}
}
}
else if (Channel == 3)
{
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
LinePD[0] = TableB[LinePS[0]];
LinePD[1] = TableG[LinePS[1]];
LinePD[2] = TableR[LinePS[2]];
LinePD[3] = TableB[LinePS[3]];
LinePD[4] = TableG[LinePS[4]];
LinePD[5] = TableR[LinePS[5]];
LinePD[6] = TableB[LinePS[6]];
LinePD[7] = TableG[LinePS[7]];
LinePD[8] = TableR[LinePS[8]];
LinePD[9] = TableB[LinePS[9]];
LinePD[10] = TableG[LinePS[10]];
LinePD[11] = TableR[LinePS[11]];
LinePS += 12;
LinePD += 12;
}
for (int X = Block * BlockSize; X < Width; X++)
{
LinePD[0] = TableB[LinePS[0]];
LinePD[1] = TableG[LinePS[1]];
LinePD[2] = TableR[LinePS[2]];
LinePS += 3;
LinePD += 3;
}
}
}
return IM_STATUS_OK;
}
这样效率能进一步的提高。
在早期我们的关注中,我也一直想再次提高这个算法的效率,但是一直因为他太简单了,而无法有进一步的提高,在使用SSE指令集时,我们也没有找到合适的指令,只有当查找表为16字节的表时,可以使用_mm_shuffle_epi8快速实现,详见【算法随记七】巧用SIMD指令实现急速的字节流按位反转算法。 一文的描述。
在我们再次接触AVX指令集,正如上一篇关于AVX指令的文章所述,他增加了非常具有特色的gather系列指令,具体有哪些如下图所示:

有一大堆啊,其实看明白了,就只有2大类,每大类里有2个小系列,每个系列里又有4中数据类型,
两大类为 :针对128位的类型的gather和针对256位的gather。
两个系列为:带mask和不带mask系列。
4中数据类型为: int32、int64、float、double。
当然,里面还有一些64为地址和32位地址的区别,因此又增加了一些列的东西,我个人认为其中最常用的函数只有4个,分别是:_mm_i32gather_epi32 、_mm256_i32gather_epi32、_mm_i32gather_ps、_mm256_i32gather_ps,我们以_mm256_i32gather_epi32为例。
注意,这里所以下,不要以为_mm_i32gather_ps这样的intrinsics指令以_mm开头,他就是属于SSE的指令,实际行他并不是,他是属于AVX2的,只是高级别的指令集对老指令的有效补充。
_mm256_i32gather_epi32的相关说明如下:
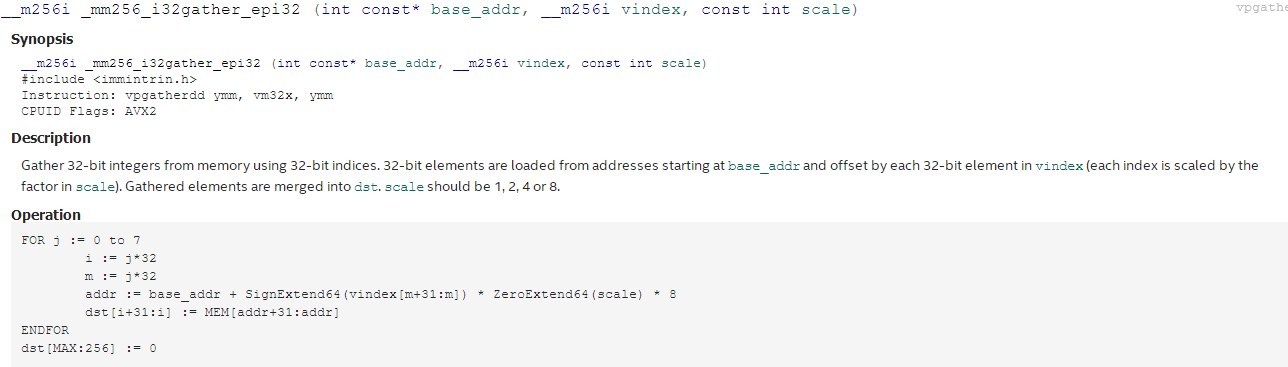
其作用,翻译过来就是从固定的基地址base_addr开始, 燃用偏移量由 vindex提供,注意这里的vindex是一个__m256i数据类型,里面的数据要把它看成8个int32类型,即保存了8个数据的地址偏移量,最后一个scale表示地址偏移量的放大系数,容许的值只有1、2、4、8,代表了字节,双字节,四字节和把字节的意思,通常_mm256_i32gather_epi32一般都是使用的4这个数据。
那么注意看这些gather函数,最下的操作单位都是int32,因此,如果我们的查找表是byte或者short类型,这个就有点困难了,正如我们上面的Cure函数一样,是无法直接使用这个函数的。
那么我我们来看看一个正常的int型表,使用两者之间大概有什么区别呢,以及是如何使用该函数的,为了测试公平,我把正常的查找表也做了展开。
int main()
{
const int Length = 4000 * 4000;
int *Src = (int *)calloc(Length, sizeof(int));
int *Dest = (int *)calloc(Length, sizeof(int));
int *Table = (int *)calloc(65536, sizeof(int));
for (int Y = 0; Y < Length; Y++) Src[Y] = rand(); // 产生的随机数在0-65535之间,正好符号前面表的大小
for (int Y = 0; Y < 65536; Y++)
{
Table[Y] = 65535 - Y; // 随意的分配一些数据
}
LARGE_INTEGER nFreq;//LARGE_INTEGER在64位系统中是LONGLONG,在32位系统中是高低两个32位的LONG,在windows.h中通过预编译宏作定义
LARGE_INTEGER nBeginTime;//记录开始时的计数器的值
LARGE_INTEGER nEndTime;//记录停止时的计数器的值
double time;
QueryPerformanceFrequency(&nFreq);//获取系统时钟频率
QueryPerformanceCounter(&nBeginTime);//获取开始时刻计数值
for (int Y = 0; Y < Length; Y += 4)
{
Dest[Y + 0] = Table[Src[Y + 0]];
Dest[Y + 1] = Table[Src[Y + 1]];
Dest[Y + 2] = Table[Src[Y + 2]];
Dest[Y + 3] = Table[Src[Y + 3]];
}
QueryPerformanceCounter(&nEndTime);//获取停止时刻计数值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(开始-停止)/频率即为秒数,精确到小数点后6位
printf("%f \n", time);
QueryPerformanceCounter(&nBeginTime);//获取开始时刻计数值
for (int Y = 0; Y < Length; Y += 16)
{
__m256i Index0 = _mm256_loadu_si256((__m256i *)(Src + Y));
__m256i Index1 = _mm256_loadu_si256((__m256i *)(Src + Y + 8));
__m256i Value0 = _mm256_i32gather_epi32(Table, Index0, 4);
__m256i Value1 = _mm256_i32gather_epi32(Table, Index1, 4);
_mm256_storeu_si256((__m256i *)(Dest + Y), Value0);
_mm256_storeu_si256((__m256i *)(Dest + Y + 8), Value1);
}
QueryPerformanceCounter(&nEndTime);//获取停止时刻计数值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(开始-停止)/频率即为秒数,精确到小数点后6位
printf("%f \n", time);
free(Src);
free(Dest);
free(Table);
getchar();
return 0;
}
直接使用这句即可完成查表工作:__m256i Value0 = _mm256_i32gather_epi32(Table, Index0, 4);
这是一个比较简单的应用场景,在我本机的测试中,普通C语言的耗时大概是27ms,AVX版本的算法那耗时大概是17ms,速度有1/3的提升。考虑到加载内存和保存数据在本代码中占用的比重明显较大,因此,提速还是相当明显的。
我们回到刚才的关于Curve函数的应用,因为gather相关指令最小的收集粒度都是32位,因此,对于字节版本的表是无论为力的,但是为了能借用这个函数实现查表,我们可以稍微对输入的参数做些手续,再次构造一个int类型的表格,即使用如下代码(弧度版本,Channel == 1):
int Table[256];
for (int Y = 0; Y < 256; Y++)
{
Table[Y] = TableB[Y];
}
这样这个表就可以用了,对于24位我们也可以用类似的方式构架一个256*3个int元素的表。
但是我们又面临着另外一个问题,即_mm256_i32gather_epi32这个返回的是8个int32类型的整形数,而我们需要的返回值确实字节数,所以这里就又涉及到8个int32数据转换为8个字节数并保存的问题,当然为了更为高效的利用指令集,我们这里考虑同时把2个__m256i类型里的16个int32数据同时转换为16个字节数,这个可以用如下的代码高效的实现:
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i SrcV = _mm_loadu_si128((__m128i *)(LinePS + X));
// int32 A0 A1 A2 A3 A4 A5 A6 A7
__m256i ValueL = _mm256_i32gather_epi32(Table, _mm256_cvtepu8_epi32(SrcV), 4);
// int32 B0 B1 B2 B3 B4 B5 B6 B7
__m256i ValueH = _mm256_i32gather_epi32(Table, _mm256_cvtepu8_epi32(_mm_srli_si128(SrcV, 8)), 4);
// short A0 A1 A2 A3 B0 B1 B2 B3 A4 A5 A6 A7 B4 B5 B6 B7
__m256i Value = _mm256_packs_epi32(ValueL, ValueH);
// byte A0 A1 A2 A3 B0 B1 B2 B3 0 0 0 0 0 0 0 0 A4 A5 A6 A7 B4 B5 B6 B7 0 0 0 0 0 0 0 0
Value = _mm256_packus_epi16(Value, _mm256_setzero_si256());
// byte A0 A1 A2 A3 A4 A5 A6 A7 B0 B1 B2 B3 B4 B5 B6 B7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Value = _mm256_permutevar8x32_epi32(Value, _mm256_setr_epi32(0, 4, 1, 5, 2, 3, 6, 7));
_mm_storeu_si128((__m128i *)(LinePD + X), _mm256_castsi256_si128(Value));
}
for (int X = Block * BlockSize; X < Width; X++)
{
LinePD[X] = TableB[LinePS[X]];
}
上面的代码里涉及到了没有按常规方式出牌的_mm256_packs_epi32、_mm256_packus_epi16等等,最后我们也是需要借助于AVX2提供的_mm256_permutevar8x32_epi32才能把那些数据正确的调整为需要的格式。
对于彩色的图像,就要稍微复杂一些了,因为涉及到RGB格式的排布,同时考虑一些对齐问题,最友好的方式就是一次性处理8个像素,24个字节,这一部分留给有兴趣的读者自行研究。
在我本机的CPU中测试呢,灰度版本的查找表大概有20%的提速,彩色版本的要稍微多一些,大概有30%左右。
这些提速其实不太明显,因为在整个过程中处理内存耗时较多,他并不是以计算为主要过程的算法,当我们某个算法中见也有查找时,并且为了计算查找表时,需要很多的数学运算去进行隐射的坐标计算时,这个时候这些隐射计算通常都是有浮点参与,或其他各种复杂的计算参与,这个时候用SIMD指令计算这些过程是能起到很大的加速作用的,在我们没有AVX2之前,使用SSE实现时,到了进行查表时通常的做法都是把前通过SSE计算得到的坐标的_m128i元素的每个值使用_mm_extract_epi32(这个是内在的SSE指令,不是用其他伪指令拼合的)提取出每个坐标值,然后在使用_mm_set相关的函数把查找表的返回值拼接成一个行的SSE变量,以便进行后续的计算,比如下面的代码:

这个时候使用AVX2的这个指令就方便了,如下所示:

注意到上面的Texture其实是个字节类型的数组,也就是一副图像,对应的C代码如下所示:
int SampleXF = IM_ClampI(ClipXF >> 16, 0, Width - 1); // 试着拆分VX和VY的符号情况分开写,减少ClampI的次数,结果似乎区别不是特别大,因此优化意义不大 int SampleXB = IM_ClampI(ClipXB >> 16, 0, Width - 1); int SampleYF = IM_ClampI(ClipYF >> 16, 0, Height - 1); int SampleYB = IM_ClampI(ClipYB >> 16, 0, Height - 1); unsigned char *SampleF = Texture + (SampleYF * Stride + SampleXF); unsigned char *SampleB = Texture + (SampleYB * Stride + SampleXB); Sum += SampleF[0] + SampleB[0];
可见这里实际上是对字节类型进行查表,所以这里最后的那个scale参数我们取的是1,即中间的偏移是以字节为单位的,但是这里其实隐含着一个问题,即如果我们取样的是图片最右下角的那个位置的像素,因为要从那个位置开始读取四个字节的内存,除非图像原始格式是BGRA的,否则,必然会读取到超出图像内存外的内存数据,这个在普通的C语言中,已改会弹出一个系统错误框,蹦的一下说访问非法内存,但是我看用这个指令似乎目前还没有遇到这个错误,哪怕认为的输入一个会犯错误的坐标。
如果是这样的话,得到的一个好处就是对于那些图像扭曲滤镜、缩放图像中哪些重新计算坐标的函数来说,不用临时构建一副同样数据的int类型图了,而可以直接放心的使用这个函数了。
最后说明一点,经过在其他一些机器上测试,似乎有些初代即使支持AVX2的CPU,使用这些函数后相应的算法的执行速度反而有下降的可能性,不知道为什么。
在我提供的SIMD指令优化的DEMO中,在 Adjust-->Exposure菜单下可以看到使用C语言和使用AVX进行查表优化的功能,有兴趣的作者可以自行比较下。
很明显,在这里SSE优化选项是无法使用的。
本文可执行Demo下载地址: https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,菜单中蓝色字体显示的部分为已经使用AVX加速的算法,如果您的硬件中不支持AVX2,可能这个DEMO你无法运行。
如果想时刻关注本人的最新文章,也可关注公众号:

标签: # 算法
留言评论